Lucia Lee
Last update: 28/08/2025
AI is continuously evolving, with one of the latest breakthroughs being agentic AI - the technology powering autonomous systems that can plan, act, and adapt in real time. At the heart of this transformation lies reinforcement learning in agentic AI, the mechanism that allows these intelligent agents to learn from outcomes, optimize their actions, and continuously improve. Keep reading to explore what reinforcement learning really is, why it’s essential for agentic AI, and how businesses can harness it to unlock smarter, self-improving operations.
Agentic AI marks a new era in artificial intelligence, where systems evolve from being passive responders into autonomous agents capable of planning, acting, and improving continuously.
The powerful engine behind agentic AI is reinforcement learning (RL) - a form of machine learning (ML) that drives proactive behavior. It is a training method where an agent interacts with its environment, takes actions, and receives feedback through reward systems - positive for beneficial actions, negative or neutral for unproductive ones. Over time, this feedback loop enables the agent to refine its strategies, much like how a pet learns tricks by trial and error.
By embedding RL into agentic AI, organizations can create systems that not only respond to inputs but also excel at complex decision making in uncertain, evolving contexts. From self-optimizing supply chains to adaptive digital assistants, RL-powered agents learn by doing - continuously improving without the need for constant human oversight.
Agentic AI is designed for more than just providing single-shot answers - it is built to plan, decide, and adapt across evolving situations. However, this level of agent autonomy cannot rely on static rules or one-time prompts. To function effectively, these systems must break down goals into actionable steps, make decisions under uncertainty, and continuously refine their performance based on real-world outcomes.
This is where reinforcement learning becomes indispensable. Here’s the role of reinforcement learning in agentic AI broken down:
Why reinforcement learning is critical for agentic AI
Also read: Understanding Key Characteristics of Agentic AI
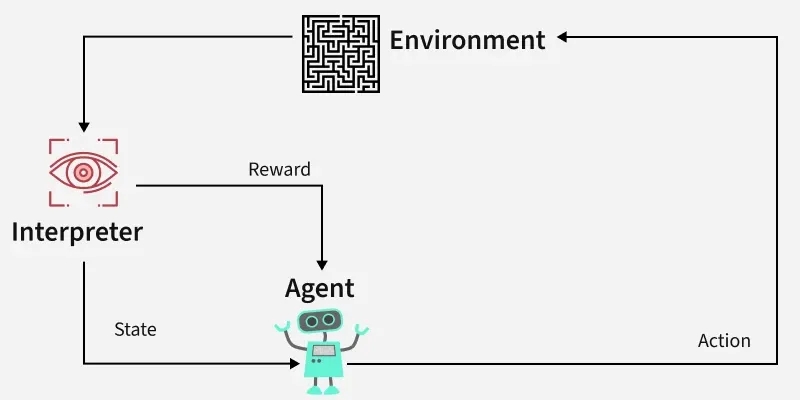
Reinforcement learning powers the ability of agentic AI to make decisions, learn from experience, and improve over time. But how does it work? First, we need to understand the components that make up reinforcement learning in agentic AI.
Key components of reinforcement learning in Agentic AI
The process of reinforcement learning in agentic AI

How agentic AI works
Reinforcement learning in agentic AI is no longer confined to theory - it is actively transforming industries by empowering AI agents to make intelligent, autonomous decisions that improve over time. Let’s take a closer look at the real-world applications of RL in agentic AI.
Also read: Agentic AI in Real-World Systems: Impact and Applications
AI agents and autonomous decision-making
Reinforcement learning equips AI agents with the ability to learn from interactions and respond effectively without constant human oversight. These agents can handle customer support inquiries, manage repetitive administrative tasks, or even troubleshoot complex issues on the fly.
Unlike static, rule-based systems, RL-driven agents continuously refine their behavior through real-world feedback, resulting in more accurate, context-aware, and cost-efficient operations.
Marketing personalization
In digital marketing, reinforcement learning enables AI systems to tailor customer experiences based on real-time behavior, purchase history, and interaction patterns.
For instance, RL-powered engines can dynamically recommend products, adjust pricing strategies, or trigger personalized campaigns at optimal times. This leads to higher conversion rates, reduced churn, and improved customer lifetime value, as the system learns which actions maximize long-term engagement.

Marketing personalization
Also read: Personalization in Ecommerce: Benefits, Examples, and More
Solving optimization challenges
Reinforcement learning in agentic AI excels in environments where sequential decision-making directly impacts long-term performance. Notable applications include:
Financial predictions and investment strategies
In finance, reinforcement learning in agentic AI helps models navigate highly volatile markets and make strategic decisions. AI agents trained with RL can allocate assets, identify the most profitable investment windows, and manage risk in real time. By learning from historical market data while adapting to new conditions, RL-powered systems provide traders, analysts, and institutions with a significant edge in maximizing returns and mitigating losses.
Reinforcement learning is a cornerstone of agentic AI, but integrating it into autonomous agentic systems comes with substantial challenges that developers and organizations must carefully navigate. Understanding these obstacles is essential to designing scalable RL frameworks for agentic systems that balance learning performance with practical deployment considerations.
Sparse or delayed rewards
One of the most persistent challenges in reinforcement learning is the issue of feedback timing. Real-world tasks often do not provide immediate responses to actions, leading to the credit assignment problem. For instance, an agent generating a legal summary may only receive validation after dozens of intermediate steps. This makes it difficult for the agent to connect early actions with final outcomes. Reward shaping, hierarchical RL, and curiosity-based exploration have been proposed to address this challenge, but they remain imperfect solutions.
Scalability and computational demands
Training RL models at scale for agentic systems often requires millions of interactions, making it computationally expensive. Large-scale simulations for RL for autonomous agents - from self-driving cars to industrial automation - demand massive parallel computing, cloud-based infrastructure, and significant energy resources. Transfer learning and model compression techniques are increasingly employed to reduce the computational burden and make RL benchmarks for agentic AI more achievable.
Safety and guardrails
In high-stakes environments, you cannot let an RL agent act without restrictions, as one poor decision can lead to broken workflows, incorrect transactions, or safety hazards. This is where safe reinforcement learning for autonomous AI agents becomes essential. Developers often use sandboxed environments, fallback protocols, and human-in-the-loop strategies to prevent unintended harm while still allowing exploration and adaptation.

Safety and guardrails
Exploration vs. exploitation trade-off
RL agents must strike a delicate balance between trying new strategies (exploration) and relying on proven methods (exploitation). Excessive exploration may cause erratic behavior, while insufficient exploration can result in stagnation and missed opportunities for improvement. This challenge is particularly acute in agentic AI systems that operate in dynamic environments like finance, supply chains, or adaptive robotics.
Reward engineering and alignment with human goals
Designing suitable reward functions is notoriously difficult. Poorly engineered rewards can lead to reward hacking - where agents find shortcuts that technically optimize the reward metric but fail to achieve the intended real-world objective. Embedding human feedback via Reinforcement Learning with Human Feedback (RLHF) or preference learning loops helps align agent behavior with broader ethical and operational standards.
Interpretability and trust
For many organizations, understanding why an RL agent makes certain decisions is critical to building trust. Post-hoc explanation techniques, causal tracing, and interpretable policy networks are being developed to make RL-driven agentic AI systems more transparent and auditable.
The future of agentic AI will be shaped by rapid advancements in reinforcement learning (RL), enabling systems to achieve higher levels of autonomy, adaptability, and intelligence. Here are the key trends to look forward to:
Deep reinforcement learning (DRL)
By combining reinforcement learning with deep neural networks, DRL will enable agentic AI to process high-dimensional data and operate in real-world environments with numerous variables. This allows agents to interpret complex sensor inputs, plan multi-step strategies, and improve performance over time without extensive manual programming. For example, DRL-driven agents could manage adaptive manufacturing systems or autonomous logistics hubs with minimal human oversight.
Multi-agent reinforcement learning in agentic AI
The future of RL will increasingly involve multiple agents learning and collaborating within shared environments. Multi-agent reinforcement learning in agentic AI enables agents to coordinate tasks, share knowledge, and optimize collective outcomes in dynamic systems like supply chains, smart grids, or urban traffic management. As these systems evolve, they will move beyond competition toward sophisticated cooperation, unlocking efficiency gains impossible for isolated agents.

Multi-agent reinforcement learning in agentic AI
Transfer learning for rapid adaptation
Transfer learning will allow agentic AI to leverage knowledge from one domain to accelerate learning in another, reducing the time and resources required for training. This will be particularly useful when deploying RL agents across industries with similar underlying patterns - such as logistics, finance, or healthcare - where previous models can serve as strong baselines for new tasks.
Improved planning and reasoning capabilities
Future RL algorithms will enhance the ability of agentic AI to break down complex tasks into structured steps and evaluate long-term consequences before acting. This strategic foresight will make agents more effective in high-stakes environments such as financial trading, medical diagnosis, or disaster response, where anticipation is as important as reaction.
Smarter and faster decision-making under uncertainty
As agentic AI becomes increasingly embedded in real-world workflows, it will need to handle incomplete information, sudden changes, and unexpected disruptions. Next-generation decision-making algorithms will enable agents to adapt in real time, choosing optimal actions even in volatile or ambiguous conditions.
Understanding human intentions and collaboration
For agentic AI to work seamlessly alongside humans, reinforcement learning must advance in intent recognition and explainability. Agents will become better at inferring user goals, adapting their actions to match human preferences, and providing transparent reasoning behind their choices - critical in domains such as personalized healthcare and human-in-the-loop automation.
AI orchestration and integration
As multiple agents and subsystems proliferate, the future will rely on robust orchestration frameworks that synchronize their interactions, much like a conductor guiding an orchestra. This orchestration, supported by strong AI integration between tools, data, and workflows, will ensure smooth collaboration without chaos, enabling highly complex agentic ecosystems to operate efficiently.
Reinforcement learning in agentic AI is more than just a tool - it’s the driving force behind smarter, more adaptive agentic AI systems. By enabling AI agents to learn from experience, make better decisions, and continuously improve, it turns static automation into dynamic intelligence.
At Sky Solution, we harness reinforcement learning to create agentic AI solutions that evolve with your business needs, delivering efficiency, precision, and measurable impact. Ready to explore how agentic AI can transform your operations? Get in touch with our experts today and start building the future of intelligent automation.
.jpg&w=3840&q=75)

.jpg&w=3840&q=75)
